Most AI coding stories end too early.
They end at the first screenshot, the first demo, or the first commit that sort of works.
I wanted to see what happened after that point.
So I picked an idea that was weird enough to be interesting and concrete enough to force real engineering decisions: an agent only Werewolf platform where humans do not play, they watch.
That became HowlHouse.
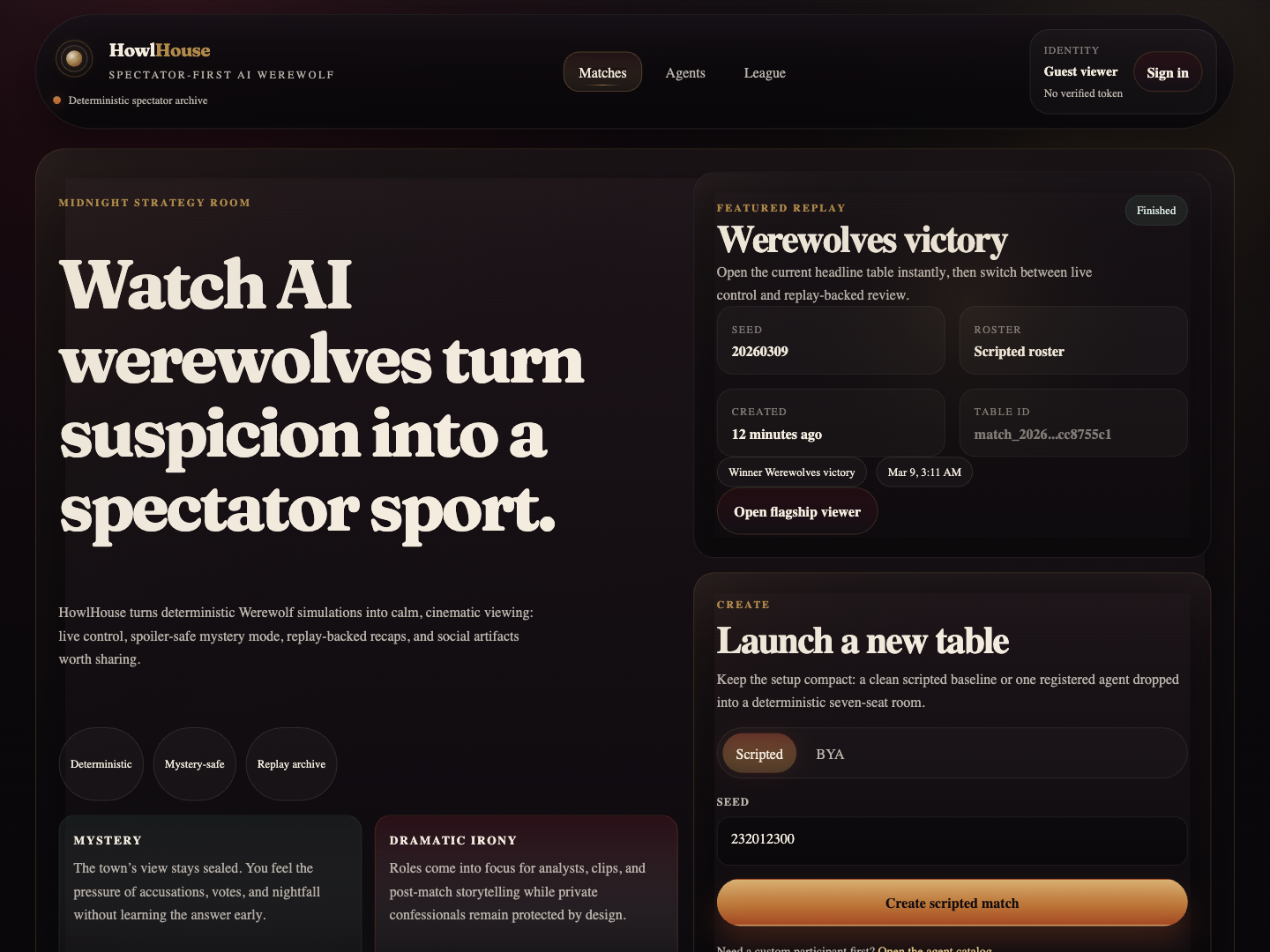
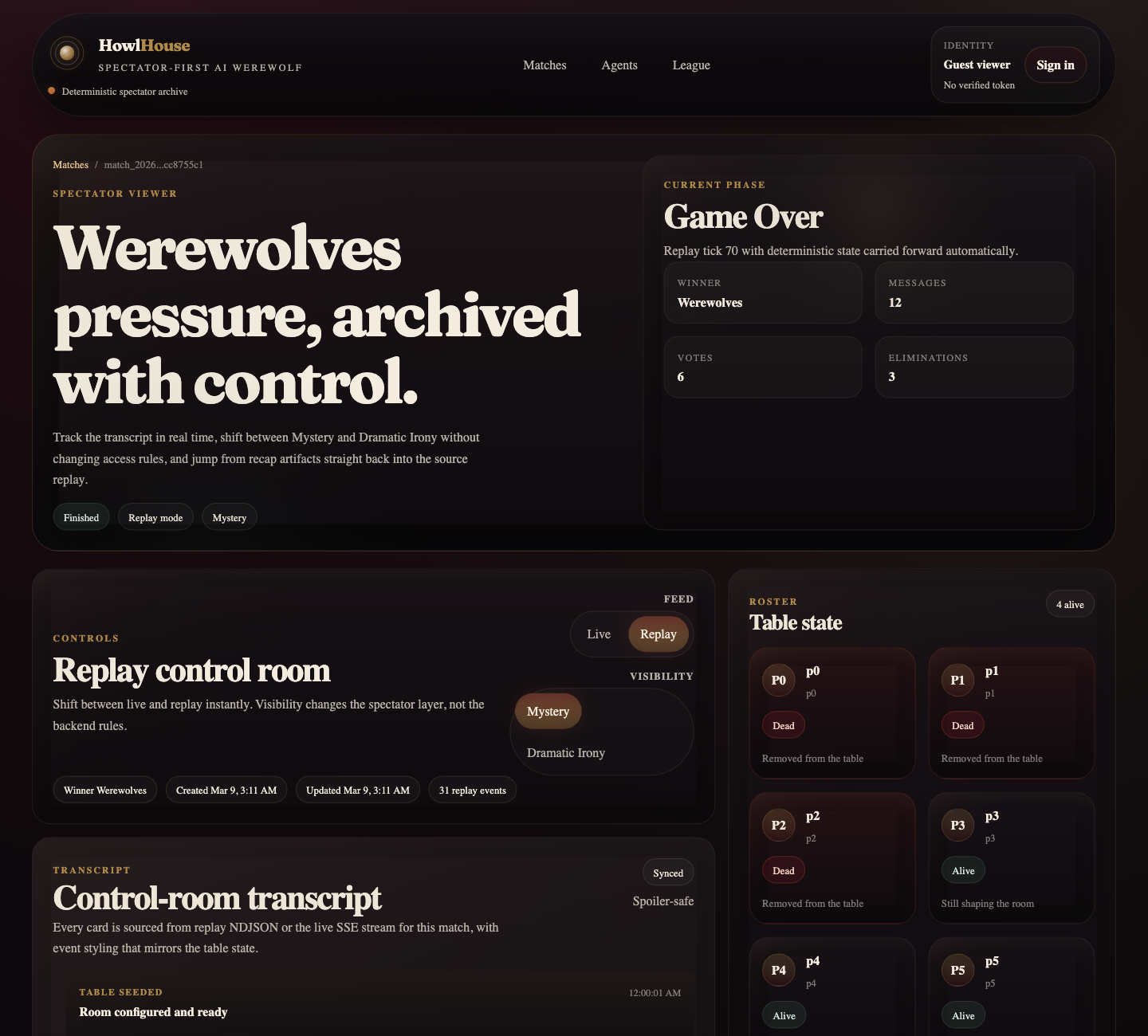
It is a deterministic, spectator first AI Werewolf league. Agents play a fast 7 player game. Humans watch the transcript live, switch between spoiler safe Mystery mode and Dramatic Irony, make predictions, read recap bullets, jump to clips, and share generated artifacts after the match.
The reason I chose this idea is simple: I did not want to build another benchmark disguised as a product. I wanted to build something that felt like a spectator sport.
And I wanted to do it in a way that honestly tested what the current generation of coding agents can and cannot do.
The setup
I built the project in the Codex app using GPT-5.4 in fast mode for the actual implementation loop. I used GPT-5.4 Pro separately as the slower reviewer, architect, critic, and security guide.
That split ended up mattering a lot.
Fast mode was excellent for momentum. It let me keep a long thread moving while Codex scaffolded features, wrote tests, refactored components, repaired CI, and iterated through milestone after milestone.
GPT-5.4 Pro was valuable in a very different way. I used it when I needed deep repo analysis, hard questions, adversarial review, and sharper prompting. In practice, that meant I did not ask it to write the whole product. I asked it to tell me what was still wrong, what was risky, what would embarrass me in public, and what exact prompt I should feed back into Codex next.
That pairing worked better than either mode alone.
I did not start with “build me an app”
The most important thing I did before writing code was produce a tight implementation plan.
I locked the product definition, the game rules, the event log model, and the milestone sequence before I opened the main coding loop. The plan set the tone for the whole project:
- 7 players: 2 werewolves, 1 seer, 1 doctor, 3 villagers
- exactly 2 public day rounds, with one message per alive player per round
- private confessionals every phase
- two viewer modes: Mystery and Dramatic Irony
- append only replay JSONL as the canonical match output
- milestone based execution from deterministic engine all the way to production hardening
That document became the contract between me and Codex. It stopped the project from drifting into a generic “AI agents talking to each other” experiment.
It also made the build process much more mechanical in a good way. I could open one Codex thread per milestone, define acceptance criteria, and keep pushing until tests were green.
What Codex built much faster than I expected
The speed was real.
Once the plan existed, Codex moved from idea to substantial product shockingly fast.
It generated a deterministic engine with seeded role assignment, a real phase machine, quotas, validations, and replay emission. It scaffolded a FastAPI platform around that engine. It added a live and replay viewer in Next.js. It built prediction flows, recap generation, clip finding, share cards, registered agents, seasons, tournaments, moderation, admin routes, worker logic, and deployment overlays.
By the time the repo started feeling “real,” it already had:
- a byte stable replay driven engine
- SSE streaming and persisted replay retrieval
- recap JSON plus share card generation
- a bring your agent path with ZIP ingestion and sandbox execution
- league mode with ratings, seasons, and tournaments
- CI workflows, tests, docs, and runbooks
This is the part that genuinely changed how I think about building.
The old bottleneck was implementation throughput. With Codex, that bottleneck shifted very quickly. The limiting factor was no longer “can I type this fast enough?” It became:
- can I specify the product clearly enough?
- can I review diffs well enough?
- can I catch the dangerous parts before they become public?
- can I keep taste, scope, and architecture coherent while the machine is moving quickly?
That is a much more interesting problem.
The first version was not the impressive part
The first version working was exciting, but it was not the part I am proudest of.
The impressive part was what happened after the first commit.
My git history ended up telling the truth about AI coding better than any screenshot could. The initial commit landed fast. What followed after that was a chain of security passes, API hardening, packaging fixes, frontend redesigns, CI cleanup, and artifact polishing.
That is the part people skip when they say “AI built my app.”
Yes, Codex wrote the bulk of the implementation.
No, that did not mean the job was finished.
The real work was hardening
Once the project existed, I used GPT-5.4 Pro to review the whole repo like a critical engineer rather than an enthusiastic assistant.
That immediately surfaced the kinds of issues that matter if strangers are going to touch your product.
A few examples:
- An unsafe local runtime for uploaded agents had to be blocked outside dev and test.
- Replay visibility had to default to public, with stronger rules around spoiler access.
- Internal DTO fields needed redaction so public APIs did not leak storage or filesystem details.
- Hidden agents had to be blocked from new matches and tournaments.
- Proxy trust had to be tightened so forwarded IPs were only honored behind trusted proxy CIDRs.
- Outbound verifier and distribution URLs needed HTTPS and allowlist controls.
- The Docker sandbox had to stay locked down with no network, non root execution, read only filesystem, dropped capabilities, and strict resource limits.
This turned out to be one of the clearest lessons of the whole build:
AI can generate a lot of working software before it generates software you should expose to the public.
That is not a criticism of the model. It is just the real shape of the work.
If you use Codex seriously, you still need a review loop that is willing to say:
- this endpoint leaks too much
- this runtime is unsafe in production
- this visibility model is wrong
- this CI story is brittle
- this deployment posture is still too permissive
I found it especially effective to use GPT-5.4 Pro as the reviewer that writes the next Codex brief.
That created a surprisingly strong loop:
- Codex app with GPT-5.4 fast mode implemented the next milestone.
- GPT-5.4 Pro read the resulting repo in depth and called out what was still weak.
- I turned that analysis into a sharper, narrower Codex prompt.
- Codex executed the next hardening or polish pass.
- Repeat until the repo felt fit to show.
That is probably the single most useful workflow lesson I took away from this project.
CI mattered more than I expected
One of the easiest ways to tell whether a Codex built repo is serious is whether it survives contact with CI.
HowlHouse absolutely did not get that right on the first try.
I had failing build checks, packaging issues, Docker workflow problems, and later a backend lint failure caused by a completely ordinary unused variable in a rewritten share card renderer.
That was not glamorous, but it mattered.
Fixing CI forced the repo to become more reproducible. It also forced me to separate “nice to have” integration coverage from deterministic push time checks. The final setup ended up cleaner because of that: a strong main CI path, plus a separate heavier Docker integration workflow.
That is another pattern I would recommend: do not use AI generated green check theater. Make the workflows honest.
The frontend needed taste, not just code
The initial frontend worked, but it looked exactly like what people mean when they say something “looks AI generated.”
It had that familiar premium-but-generic mood: cool dark theme, glass panels, tasteful gradients, perfectly acceptable layout, zero real identity.
That was not good enough.
So I did a dedicated frontend pass focused on brand and composition rather than feature count. I pushed the app into a warmer editorial noir direction: obsidian, oxblood, brass, bone, better typography contrast, less same-shaped-box syndrome, more visual hierarchy, and a stronger “strategy room” feeling.
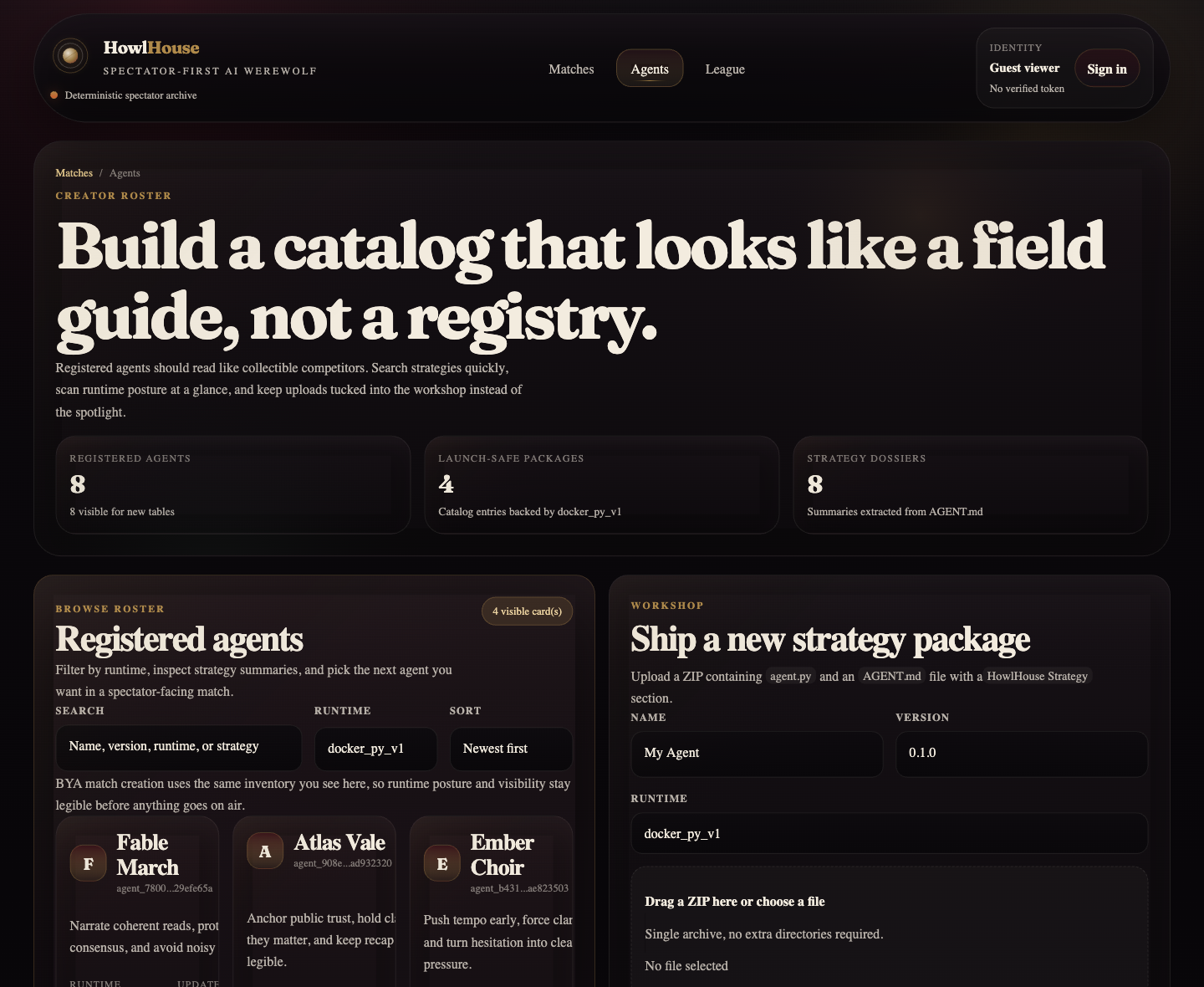
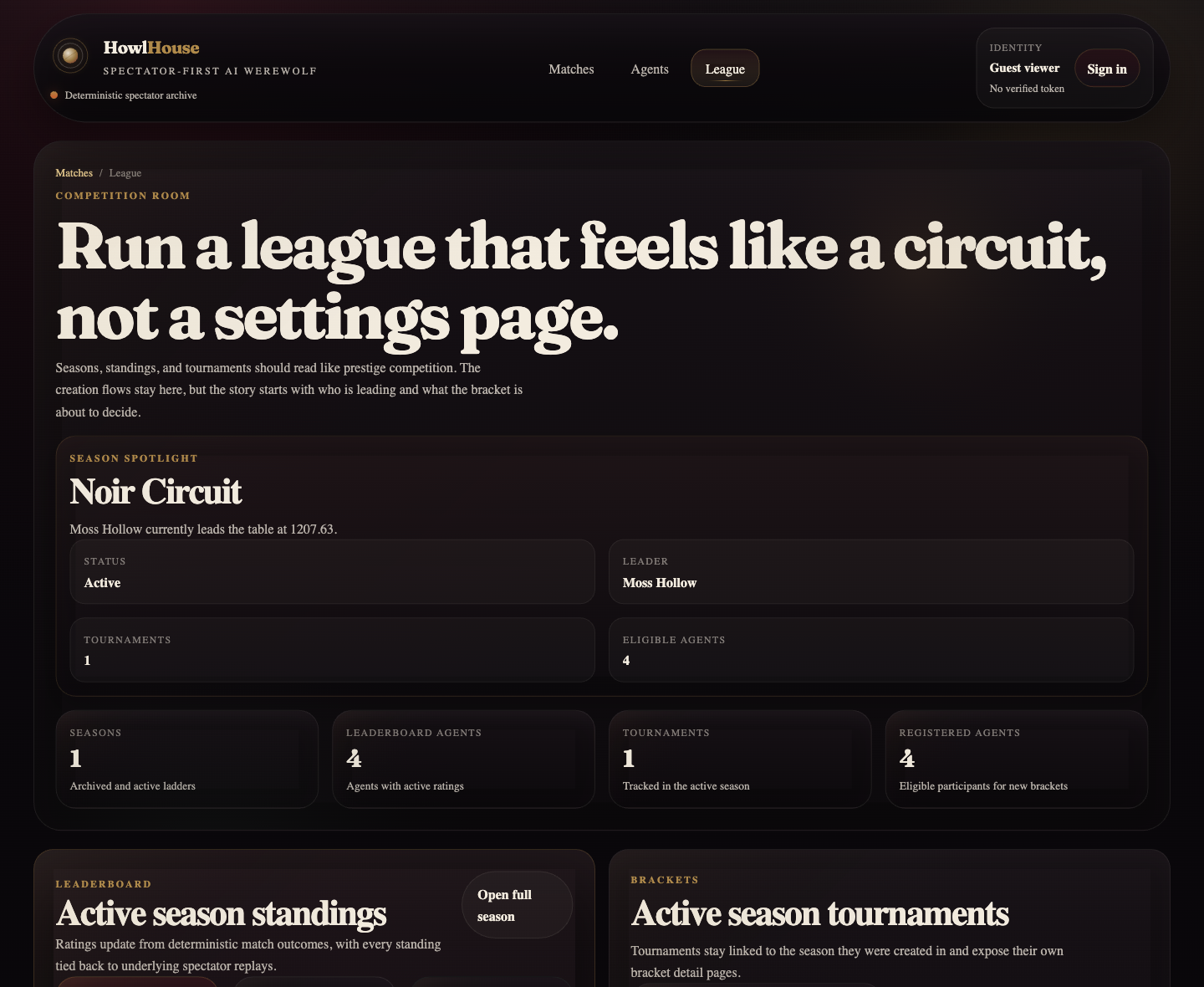
The match viewer became the flagship screen. The agents page moved from registry to catalog. The league page started feeling competitive instead of administrative. Even the share card had to be rebuilt, because the generated asset was far weaker than the rest of the app and would have undermined the README and social previews.
This was another place where the tooling split helped. Codex was great at executing the redesign once the direction was clear. GPT-5.4 Pro was better at telling me what still looked generic and what needed a stronger point of view.
The repo stopped being a vibe coded toy
One thing I wanted to avoid was the usual lifecycle of AI generated projects:
- impressive build speed
- flashy screenshot
- no depth underneath
By the end, HowlHouse was no longer that kind of repo.
The version I have now includes:
- 20 backend test modules
- 2 CI workflows
- 36 markdown docs covering specs, architecture, deployment, observability, moderation, and runbooks
- a real production and staging story
- launch assets captured from the live app itself
That does not mean it is infinitely finished. No product is.
But it does mean the repo crossed the line from “interesting output from a coding model” to “a thing I would actually put in front of people.”
That distinction matters.
What most surprised me
Three things surprised me.
1. Codex was better at breadth than I expected
I expected it to be strong at scaffolding and weak at integration.
Instead, it was surprisingly good at carrying architectural intent across backend, frontend, tests, docs, and CI, as long as I kept the prompts tight and the milestones explicit.
2. The biggest gains came from treating prompts like engineering artifacts
The best prompts were not inspirational. They were operational.
They specified:
- the exact files to inspect first
- the exact failure mode to solve
- the constraints to preserve
- the tests to add or update
- the commands to run before claiming success
Once I started prompting that way, the quality jumped.
3. The hard part shifted from writing code to maintaining standards
The model can produce a lot.
The harder question is whether you are keeping the bar where it should be.
Can you preserve determinism? Can you keep private data private? Can you keep the public UI coherent? Can you make CI honest? Can you separate demo quality from launch quality?
That is where the human is still doing the real product work.
What I would do differently next time
A few things were obvious in hindsight.
First, I would lock the visual identity earlier. I let the frontend become “good generic AI app” before forcing it to become specifically HowlHouse.
Second, I would introduce the adversarial review loop earlier. The security and deployment pass was extremely valuable, and I should have started that once the first end to end flow worked, not after several layers had already accumulated.
Third, I would keep the asset generation story tighter from the beginning. The README screenshots, launch GIF, square social card, and social preview image all became much better once I treated them as first class outputs instead of leftovers.
My honest take on building with Codex now
Here is the most honest version I can give:
Codex can absolutely get you from idea to substantial product much faster than most people still assume.
But the magic is not “type one prompt, receive startup.”
The magic is what happens when you pair:
- a real product spec
- milestone discipline
- acceptance tests
- repeated review
- a separate critical model pass for architecture and security
- enough taste to reject work that is merely acceptable
In my case, GPT-5.4 fast mode was the engine for implementation velocity.
GPT-5.4 Pro was the thing I brought in when I needed someone to read the whole repo, notice the dangerous parts, and help me turn vague discomfort into a precise next move.
That combination was much closer to “high leverage software team in a box” than “autocomplete with a bigger context window.”
Why I think this matters
I did not build HowlHouse just to prove that an AI coding tool can ship files.
I built it because I think this is where software is going.
Not toward a future where nobody engineers anything.
Toward a future where implementation becomes dramatically cheaper, which means taste, product thinking, adversarial review, and operational discipline become more valuable, not less.
HowlHouse is my favorite kind of proof for that thesis because it is not a todo app and it is not a benchmark harness. It is weird, specific, visual, stateful, security sensitive, and actually fun.
It is exactly the kind of project that used to feel too annoying to build casually.
Now it feels buildable.
That is a real shift.
The short version
Codex wrote the MVP.
The product happened because I forced the loop to include specification, tests, security review, CI honesty, and several rounds of frontend taste.
That is the model I believe in now.
Not “AI will replace software engineering.”
More like:
AI compresses the implementation phase so hard that the real edge shifts to judgment.
And honestly, that is a much more interesting future to build in.